import pandas as pd
import numpy as np
import datetime
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings("ignore")Maitrise des données financières avec Python
news
Introduction
Les données financières sont très utilisées dans la filière gestion des risques de l’ENSAI. Avoir rapidement accès est un atout pour les étudiants et les fera gagner du temps. Ces données sont utilisées dans plusieurs cours notamment le cours de séries temporelles, le cours de la théorie de gestion des risques multiples,le cours d’asset pricing, etc. C’est pourquoi j’ai décidé de partager avec vous quelques astuces pour maitriser les données financières avec Python. Nous utiliserons la librairie yfinance pour récupérer les données financières et pandas pour les manipuler et matplotlib pour les visualiser.
J’ai importé la library datetime pour manipuler les dataes. Maintenant, nous pouvons importer les données.
Importer les données
import yfinance as yf
aapl = yf.download('AAPL',
start='2012-01-01',
end='2024-01-01',)
aapl.head() [*********************100%%**********************] 1 of 1 completed| Open | High | Low | Close | Adj Close | Volume | |
|---|---|---|---|---|---|---|
| Date | ||||||
| 2012-01-03 | 14.621429 | 14.732143 | 14.607143 | 14.686786 | 12.433825 | 302220800 |
| 2012-01-04 | 14.642857 | 14.810000 | 14.617143 | 14.765714 | 12.500644 | 260022000 |
| 2012-01-05 | 14.819643 | 14.948214 | 14.738214 | 14.929643 | 12.639428 | 271269600 |
| 2012-01-06 | 14.991786 | 15.098214 | 14.972143 | 15.085714 | 12.771556 | 318292800 |
| 2012-01-09 | 15.196429 | 15.276786 | 15.048214 | 15.061786 | 12.751299 | 394024400 |
Le code ci-dessus utilise la fonction downloadde la librairir yfinance pour télécharger les données de la société Apple (AAPL) de 2012 à 2024. De la même manière, vous pouvez télécharger les données d’autres sociétés. Par exemple, pour accèder aux données du CAC40, vous pouvez utiliser le code suivant:
cac40 = yf.download('^FCHI',
start='2012-01-01',
end='2024-01-01',)
cac40.head()[*********************100%%**********************] 1 of 1 completed| Open | High | Low | Close | Adj Close | Volume | |
|---|---|---|---|---|---|---|
| Date | ||||||
| 2012-01-03 | 3231.429932 | 3246.739990 | 3193.629883 | 3245.399902 | 3245.399902 | 123415200 |
| 2012-01-04 | 3227.459961 | 3242.840088 | 3186.479980 | 3193.649902 | 3193.649902 | 114040800 |
| 2012-01-05 | 3197.159912 | 3200.149902 | 3136.750000 | 3144.909912 | 3144.909912 | 121161600 |
| 2012-01-06 | 3156.419922 | 3184.379883 | 3122.629883 | 3137.360107 | 3137.360107 | 104492800 |
| 2012-01-09 | 3143.949951 | 3157.310059 | 3114.449951 | 3127.689941 | 3127.689941 | 96976800 |
Nous savons que pour les données de marché, nous avons les colonnes suivantes: Open, High, Low, Close, Adj Close, Volume. Nous allons maintenant travailler avec la colonne Close qui représente le prix de clôture de l’action. Nous pouvons maintenant visualiser les données.
plt.figure(figsize=(10, 6))
plt.plot(aapl['Close'], label='AAPL')
plt.title('Prix de clôture de l\'action AAPL')
plt.xlabel('Date')
plt.ylabel('Prix de clôture')
plt.legend()
plt.show()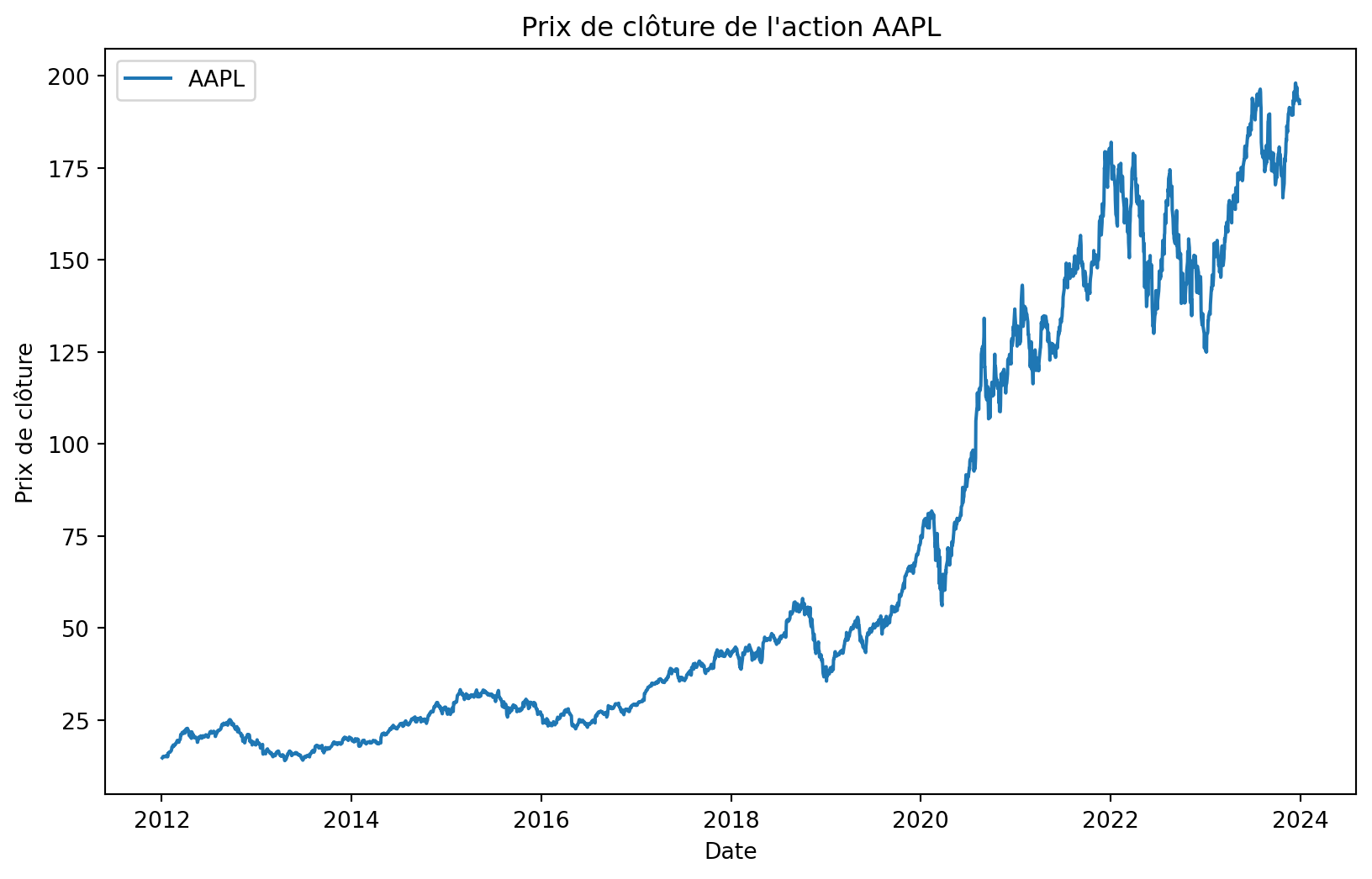
Ces données ne sont pas stationnaires. Généralement, pour les données financières, nous travaillons avec les rendements car ils sont stationnaires. Si \(P_t\) est le prix de l’action à la date \(t\), le rendement à la date \(t\) est donné par: \[ r_t = \frac{P_t - P_{t-1}}{P_{t-1}} \]
est équivalent à
\[ \log\left(1 + \frac{P_t - P_{t-1}}{P_{t-1}}\right) = \log\left(\frac{P_t}{P_{t-1}}\right) \]
Donc nous travaillons avec le logarithme des rendements. Nous pouvons maintenant calculer les rendements. Il existe une fonction pct_change dans la librairie pandas qui permet de calculer les rendements. Nous allons utiliser cette fonction combinée avec la fonction log de la librairie numpy pour calculer les logarithmes des rendements du prix de clôture de l’action AAPL.
daily_close = aapl[['Close']]
daily_close_returns = daily_close.pct_change().apply(lambda x: np.log(1+x))
daily_close_returns.head()| Close | |
|---|---|
| Date | |
| 2012-01-03 | NaN |
| 2012-01-04 | 0.005360 |
| 2012-01-05 | 0.011041 |
| 2012-01-06 | 0.010400 |
| 2012-01-09 | -0.001587 |
Dans le code ci-dessus nous avons utilisé l’expression ci-dessous pour calculer les rendements: \[ \log\left(1 + \frac{P_t - P_{t-1}}{P_{t-1}}\right) \]
Nous pouvons plutôt utiliser la fonction log de la librairie numpy pour calculer les rendements à partir de l’expression ci-dessous: \[
\log\left(\frac{P_t}{P_{t-1}}\right)
\]
daily_close_returns = np.log(daily_close / daily_close.shift(1))
daily_close_returns.head()| Close | |
|---|---|
| Date | |
| 2012-01-03 | NaN |
| 2012-01-04 | 0.005360 |
| 2012-01-05 | 0.011041 |
| 2012-01-06 | 0.010400 |
| 2012-01-09 | -0.001587 |
Nous avons les mêmes résultats avec la première valeur qui est NaN. Nous pouvons supprimer cette valeur.
daily_close_returns = daily_close_returns.dropna()
daily_close_returns.head()| Close | |
|---|---|
| Date | |
| 2012-01-04 | 0.005360 |
| 2012-01-05 | 0.011041 |
| 2012-01-06 | 0.010400 |
| 2012-01-09 | -0.001587 |
| 2012-01-10 | 0.003574 |
Nous pouvons maintenant visualiser les rendements.
daily_close_returns.plot(figsize=(10, 6))
plt.title('Logarithme des rendements du prix de clôture de l\'action AAPL')
plt.xlabel('Date')
plt.ylabel('Logarithme des rendements')
plt.show()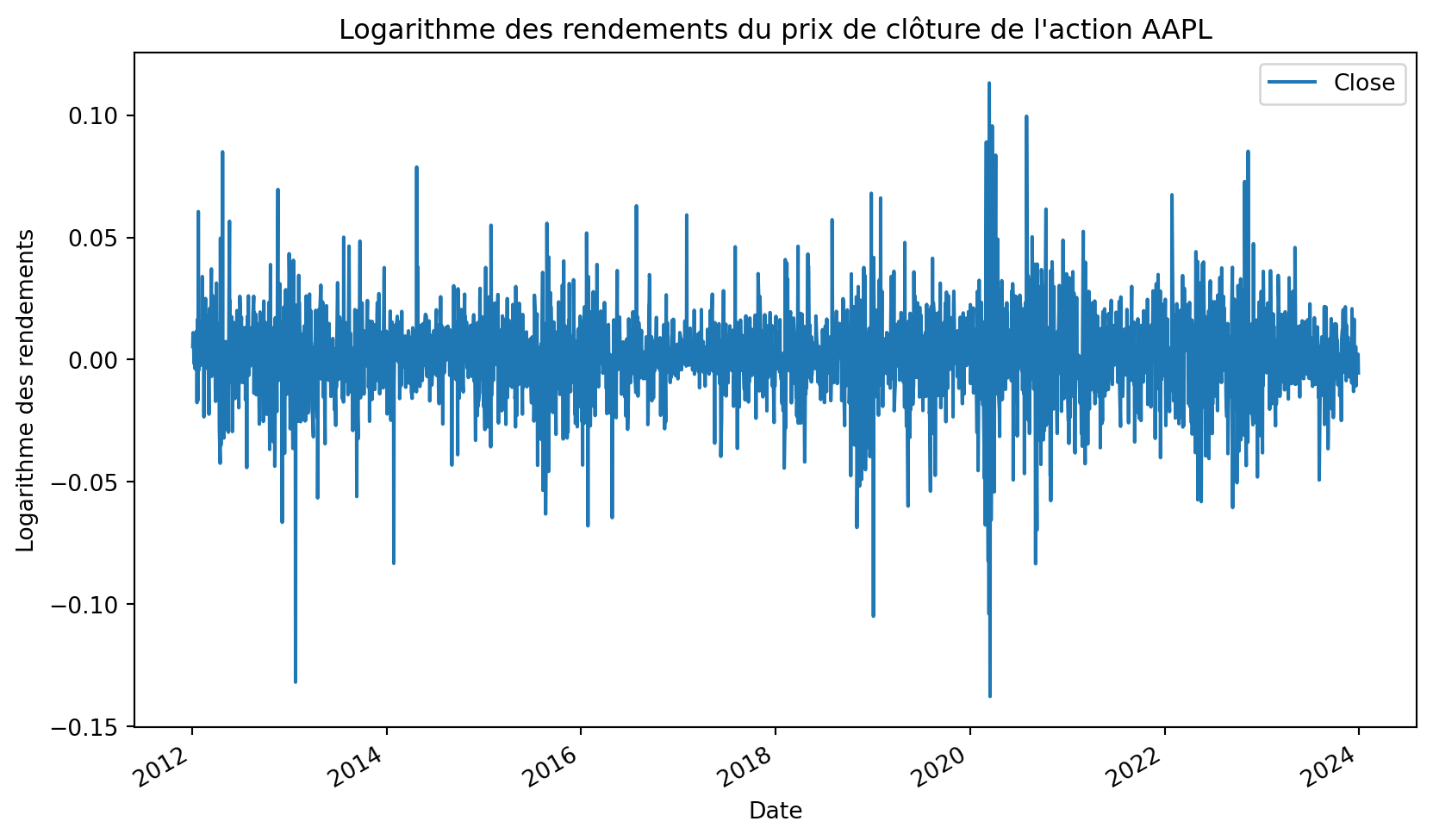
Si vous voulez, vous pouvez étudier les statistiques descriptives des rendements. Une fonction que j’adore qui donne les statistiques sommaire est la fonction describe de la librairie pandas.
daily_close_returns.describe()| Close | |
|---|---|
| count | 3017.000000 |
| mean | 0.000853 |
| std | 0.017967 |
| min | -0.137708 |
| 25% | -0.007562 |
| 50% | 0.000765 |
| 75% | 0.010275 |
| max | 0.113157 |
Nous pouvons aussi rééchantillonner les données pour avoir les log rendements minimums, maximums, moyens, etc. par semaine, par mois, par trimestre,etc. Par exemple pour avoir les log rendements moyens par semaine, nous pouvons utliser la fonction resample de la librairie pandas combinée avec la fonction mean pour avoir les moyennes.
weekly = daily_close_returns.resample('W').mean()
weekly.head()| Close | |
|---|---|
| Date | |
| 2012-01-08 | 0.008933 |
| 2012-01-15 | -0.001230 |
| 2012-01-22 | 0.000292 |
| 2012-01-29 | 0.012443 |
| 2012-02-05 | 0.005469 |
Je vais terminer ce poste par vous montrer comment télécharger les données de plusieurs sociétés. Par exemple, pour télécharger les données de Apple, Microsoft, Google et Amazon, vous pouvez utiliser le code suivant:
import yfinance as yf
tickers = ['AAPL', 'MSFT', 'GOOGL', 'AMZN']
def get_data(tickers, startdate, enddate):
def data(ticker):
return (yf.download(ticker, start=startdate, end=enddate))
datas = map(data, tickers)
return(pd.concat(datas,keys= tickers, names=['Ticker', 'Date']))
all_data = get_data(tickers, '2012-01-01', '2024-01-01')
all_data.head()[*********************100%%**********************] 1 of 1 completed
[*********************100%%**********************] 1 of 1 completed
[*********************100%%**********************] 1 of 1 completed
[*********************100%%**********************] 1 of 1 completed| Open | High | Low | Close | Adj Close | Volume | ||
|---|---|---|---|---|---|---|---|
| Ticker | Date | ||||||
| AAPL | 2012-01-03 | 14.621429 | 14.732143 | 14.607143 | 14.686786 | 12.433825 | 302220800 |
| 2012-01-04 | 14.642857 | 14.810000 | 14.617143 | 14.765714 | 12.500644 | 260022000 | |
| 2012-01-05 | 14.819643 | 14.948214 | 14.738214 | 14.929643 | 12.639428 | 271269600 | |
| 2012-01-06 | 14.991786 | 15.098214 | 14.972143 | 15.085714 | 12.771556 | 318292800 | |
| 2012-01-09 | 15.196429 | 15.276786 | 15.048214 | 15.061786 | 12.751299 | 394024400 |
Conclusion
J’espère que ce poste vous sera utile. Si vous avez des questions, n’hésitez pas à me contacter si chatgpt ne peut pas vous aider.