Nous considérons l’expérience aléatoire consistant à lancer 3 fois une pièce de monnaie. Soit \(X\) la variable aléatoire donnant le nombre de « Pile » obtenu.
Donner la loi de la variable aléatoire \(X\).
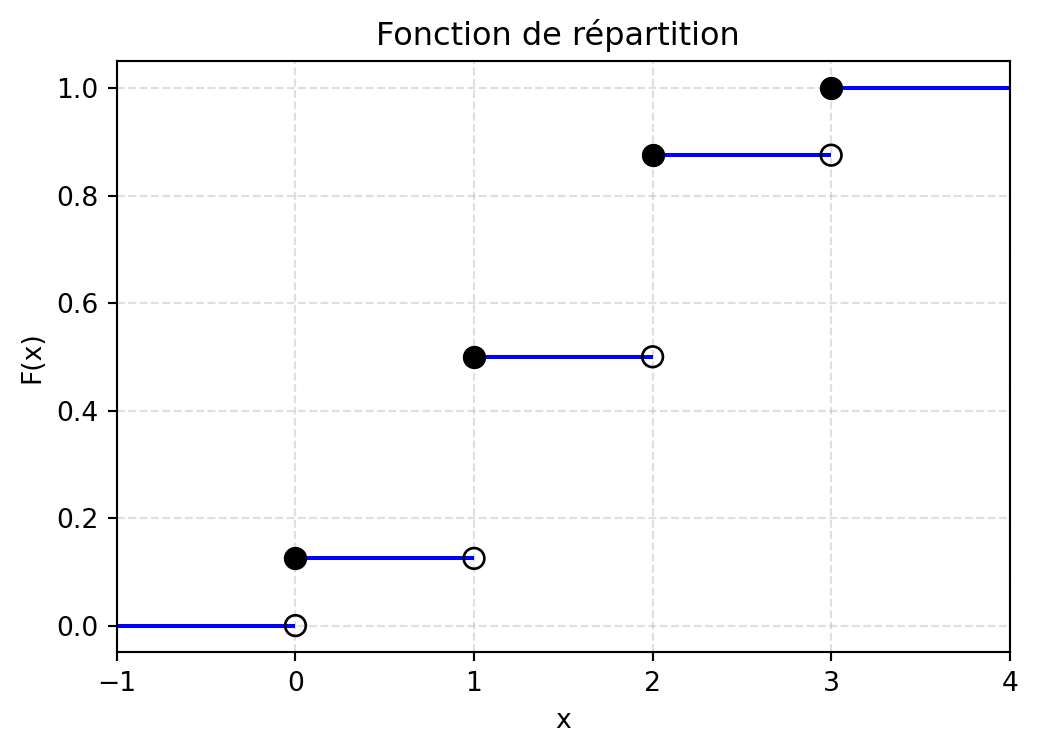
Donner la fonction de répartition de \(X\), et la représenter graphiquement.
Calculer l’espérance, la variance et le coefficient de variation de \(X\).
Correction de l’exercice 1
Nous considérons l’espace probabilisé \((\Omega, \mathcal{F}, P)\) associé à l’expérience aléatoire de lancer 3 fois une pièce de monnaie. L’ensemble des résultats possibles \(\Omega\) est donné par :
Nous munissons cet espace de la tribu \(\mathcal{F}\) des parties de \(\Omega\) et de la probabilité uniforme \(P\).
La variable aléatoire \(X\) est définie comme le nombre de « Pile » obtenus lors des 3 lancers. Ainsi, \(X\) peut prendre les valeurs suivantes : - \(X = 0\) : lorsque le résultat est FFF - \(X = 1\) : lorsque le résultat est PFF, FPF, ou FFP - \(X = 2\) : lorsque le résultat est PPF, PFP, ou FPP - \(X = 3\) : lorsque le résultat est PPP
Cette variable est donc définie comme suit :
\[
X : \Omega^3 \longrightarrow \Omega' = \{0,1,2,3\}
\]
Réprésentation graphique de la fonction de répartition :
Show the code
import numpy as npimport matplotlib.pyplot as pltdef F(x): x = np.asarray(x)return np.where( x <0, 0, np.where( x <1, 1/8, np.where( x <2, 4/8, np.where( x <3, 7/8,1 ) ) ) )# Segments horizontaux de la fonction de répartitionsegments = [ (-1, 0, 0), # de x=-1 à x=0 : F=0 (0, 1, 1/8), (1, 2, 4/8), (2, 3, 7/8), (3, 4, 1)]plt.figure(figsize=(6,4))# Tracé des segments horizontaux uniquementfor x_start, x_end, y_val in segments: plt.hlines(y_val, x_start, x_end, colors="blue")# Points ouverts (limite à gauche non incluse)x_open = [0, 1, 2, 3]y_open = [0, 1/8, 4/8, 7/8]plt.scatter(x_open, y_open, facecolors="none", edgecolors="black", s=60, zorder=3)# Points fermés (valeur incluse)x_closed = [0, 1, 2, 3]y_closed = [1/8, 4/8, 7/8, 1]plt.scatter(x_closed, y_closed, color="black", s=60, zorder=3)# Format graphiqueplt.xlabel("x")plt.ylabel("F(x)")plt.title("Fonction de répartition ")plt.grid(True, linestyle="--", alpha=0.4)plt.xlim(-1, 4)plt.ylim(-0.05, 1.05)plt.show()
Espérance, variance et coefficient de variation
Pour calculer l’espérance, la variance et le coefficient de variation de la variable aléatoire \(X\), nous allons utiliser la formule de transfert en temps discret :
\[
\mathbb{E}[g(X)] = \sum_{i} g(x_i) \cdot \mathbb{P}_X(x_i),
\] où \(g\) est une fonction mésurable.
Nous considérons l’expérience aléatoire consistant à jeter un dé jusqu’à obtenir un « 6 ». Soit \(X\) la variable aléatoire donnant le nombre de jets.
Donner la loi de la variable aléatoire \(X\).
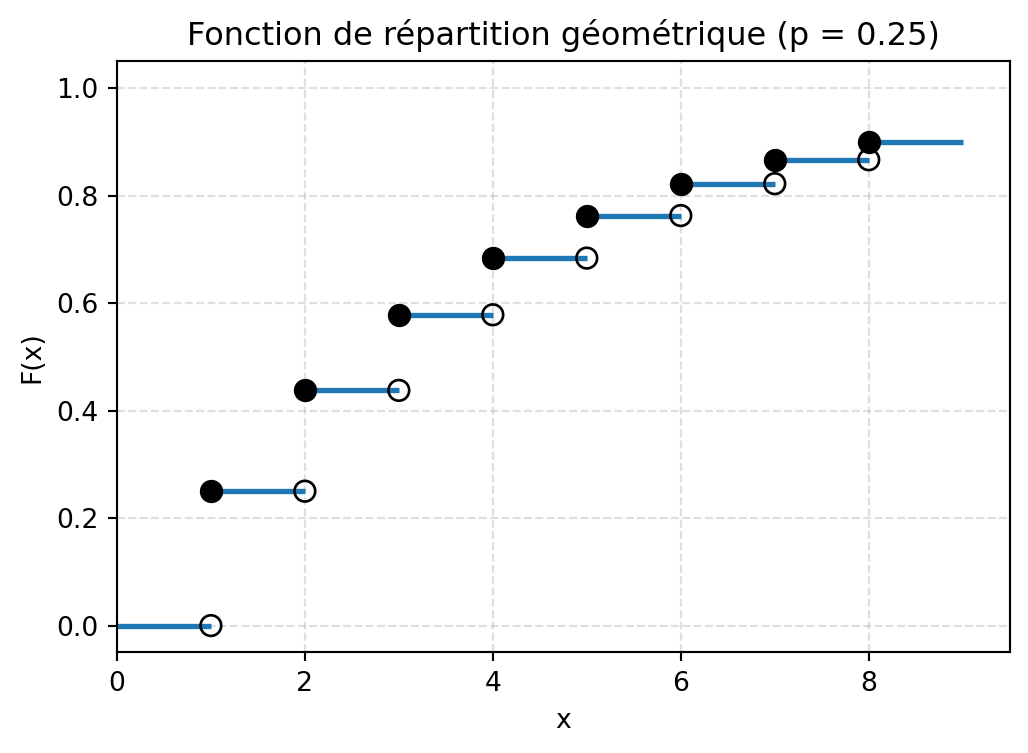
Donner la fonction de répartition de \(X\), et la représenter graphiquement.
Montrer que la fonction génératrice des moments de \(X\) vaut :
\[
M_X(t) = \frac{pe^t}{1 - e^t(1 - p)},
\]
avec \(p = \frac{1}{6}\).
En déduire l’espérance et la variance de \(X\), puis son coefficient de variation.
Correction de l’exercice 2
Loi de la variable aléatoire X
Nous considérons l’espace probabilisé \((\Omega^{\mathbb{N}}, \mathcal{P}(\Omega^{\mathbb{N}}), \mathbb{P})\) avec \(\Omega = \{1,2,3,4,5,6\}\) muni de la tribu produit et de la probabilité uniforme \(\mathbb{P}\).
L’univers \(\Omega^{\mathbb{N}}\) correspond à l’ensemble des suites infinies de résultats de lancers de dé. Autrement dit on peut l’écrire comme l’ensemble des suites infinies : \[
\Omega^{\mathbb{N}} = \{(\omega_1, \omega_2, \ldots) \mid \omega_i \in \Omega = \{1,2,3,4,5,6\} \text{ pour tout } i \in \mathbb{N}\}.
\]
La variable aléatoire étudiée est
\[
X : \Omega^{\mathbb{N}} \longrightarrow \Omega' = \mathbb{N}^*
\]
A partir de la définition de la fonction de répartition, nous obtenons
\[
F_X(x) =
\begin{cases}
0 & \text{si } x < 1,\\[4pt]
p & \text{si } 1 \leq x < 2,\\[4pt]
& \cdots,\\[4pt]
1-(1-p)^k & \text{si } k \leq x < k+1,\\[4pt]
& \cdots.
\end{cases}
\]
Représentation graphique de la fonction de répartition :
Show the code
import numpy as npimport matplotlib.pyplot as pltdef plot_cdf_geometrique(p=0.3, k_max=8):""" Trace la fonction de répartition F_X(x) = 0 si x < 1 = 1 - (1-p)^k si k <= x < k+1 pour k = 1,2,... avec une troncature à k_max. """ifnot (0< p <1):raiseValueError("p doit être dans l'intervalle (0, 1).") plt.figure(figsize=(6, 4))# Segment avant 1 : F(x) = 0 pour 0 <= x < 1 plt.hlines(0, 0, 1, linewidth=2)# Segments horizontaux pour k = 1,...,k_maxfor k inrange(1, k_max +1): level =1- (1- p)**k plt.hlines(level, k, k +1, linewidth=2)# Points ouverts (limite à gauche, non incluse) x_open, y_open = [], []# Points fermés (valeur de la FDR) x_closed, y_closed = [], []for k inrange(1, k_max +1):# Limite à gauche en k :if k ==1: left_limit =0else: left_limit =1- (1- p)**(k -1) value_at_k =1- (1- p)**k x_open.append(k) y_open.append(left_limit) x_closed.append(k) y_closed.append(value_at_k)# Cercles ouverts (non remplis) : limite à gauche plt.scatter( x_open, y_open, facecolors="none", edgecolors="black", s=60, zorder=3 )# Cercles fermés (remplis) : valeur de F_X en k plt.scatter( x_closed, y_closed, color="black", s=60, zorder=3 )# Mise en forme plt.xlabel("x") plt.ylabel("F(x)") plt.title(f"Fonction de répartition géométrique (p = {p})") plt.xlim(0, k_max +1.5) plt.ylim(-0.05, 1.05) plt.grid(True, linestyle="--", alpha=0.4) plt.show()# Exemple d'appelplot_cdf_geometrique(p=0.25, k_max=8)
Fonction génératrice des moments
En utilisant la formule de transfert en temps discret, nous avons : \[
M_X(t) = \int e^{tX} d\mathbb{P} = \sum_{x=1}^{\infty} e^{tx}\mathbb{P}_X(x)
\]
La série converge si et seulement si \(|q| < 1\), c’est-à-dire si \(|e^t(1-p)| < 1\), soit \(e^t < \frac{1}{1-p}\), ce qui donne \(t < \ln\left(\frac{1}{1-p}\right) = -\ln(1-p)\).
Espérance, variance et coefficient de variation
Nous savons que la fonction \(M_X\) est indéfiniment dérivable dans un voisinage de 0, et que \(M'_X(0) = E(X)\) et \(M''_X(0) = E(X^2)\). Nous avons après calcul
Soit \(X\) une variable aléatoire admettant un moment d’ordre 2. Nous notons \(m = E(X)\) et \(\sigma^2 = V(X)\). Soient \(X_1, \ldots, X_n\) des variables aléatoires indépendantes et de même loi que \(X\). Nous notons
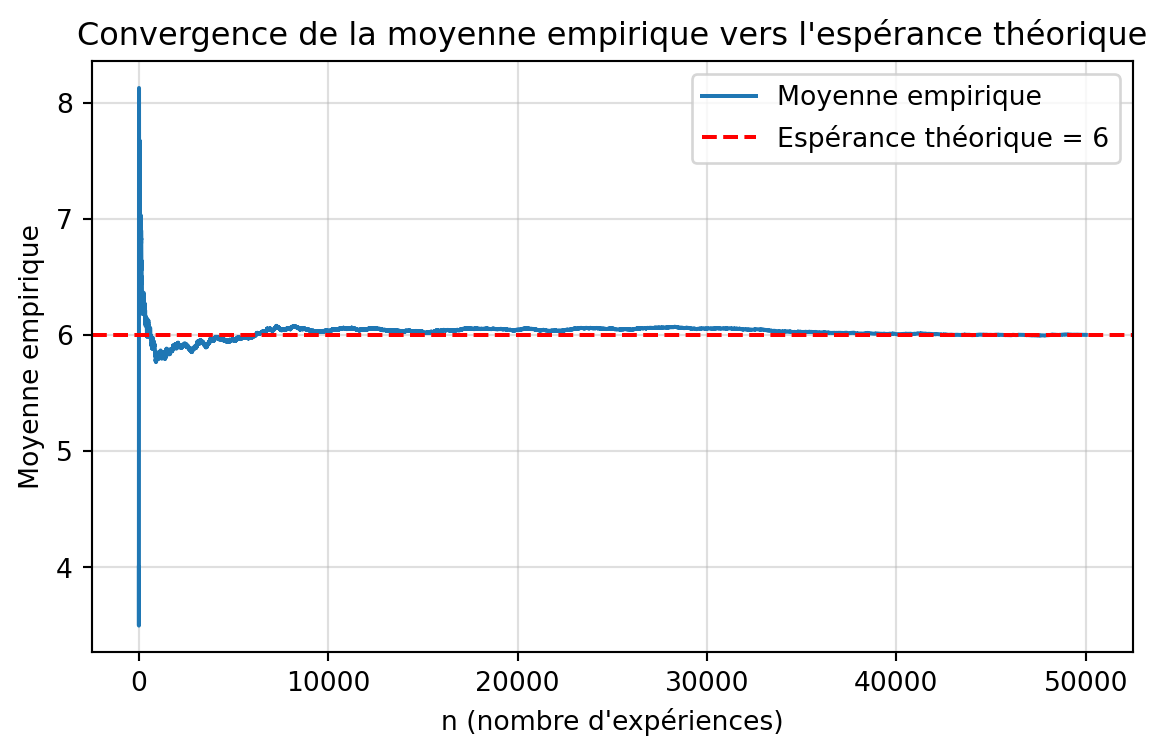
Utiliser ces résultats pour obtenir une approximation de Monte-Carlo de l’espérance, la variance et le coefficient de variation de la variable aléatoire \(X\) de l’exercice 2.
Démonstration de l’équivalence des formules de variance
Premier terme : \[\sum_{i=1}^{n}\sum_{\substack{j=1\\j\neq i}}^{n}X_i^2 = \sum_{i=1}^{n}X_i^2 \cdot (n-1) = (n-1)\sum_{i=1}^{n}X_i^2\]
Car pour chaque \(i\) fixé, \(X_i^2\) est sommé \((n-1)\) fois (pour tous les \(j \neq i\)).
Troisième terme : Par symétrie, le troisième terme donne le même résultat : \[\sum_{i=1}^{n}\sum_{\substack{j=1\\j\neq i}}^{n}X_j^2 = (n-1)\sum_{j=1}^{n}X_j^2 = (n-1)\sum_{i=1}^{n}X_i^2\]
Deuxième terme : \[\sum_{i=1}^{n}\sum_{\substack{j=1\\j\neq i}}^{n}X_iX_j\]
Pour chaque paire \((i,j)\) avec \(i \neq j\), le produit \(X_iX_j\) apparaît dans cette double somme. On peut réécrire :
Ce que nous avons montré aux points précédents, est que nous pouvons estimer l’espérance et la variance de la variable aléatoire \(X\) en utilisant les statistiques d’échantillon \(\overline{X}_n\) et \(s_X^2\). C’est-à-dire en générant un grand nombre de réalisations indépendantes de \(X\) et en calculant la moyenne empirique et la dispersion de ces réalisations.
Voici un exemple de code R pour effectuer cette approximation de Monte-Carlo pour la variable aléatoire \(X\) de l’exercice 2 :
# Monte Carlo approximation in R# Répétition de l'expérience aléatoire# Simulation du nombre de lancers nécessaires pour obtenir un 6set.seed(360)n <- 50000ctr <- 0simlist <- numeric(n)while (ctr < n) { ctr <- ctr + 1 # Valeur du lancer (initialisation) trial <- 0 # Nombre de tentatives (initialisation) nb_tent <- 0 while (trial != 6) { nb_tent <- nb_tent + 1 trial <- sample(1:6, 1) } simlist[ctr] <- nb_tent}# Affichage des résultatsmean(simlist)var(simlist)# Statistiques supplémentairescat("\n=== Résultats de la simulation ===\n")cat("Nombre de simulations:", n, "\n")cat("Moyenne du nombre de lancers:", mean(simlist), "\n")cat("Variance:", var(simlist), "\n")cat("Écart-type:", sd(simlist), "\n")cat("Minimum:", min(simlist), "\n")cat("Maximum:", max(simlist), "\n")cat("Médiane:", median(simlist), "\n")# Histogrammehist(simlist, breaks = 30, col = "lightblue", border = "white", main = "Distribution du nombre de lancers pour obtenir un 6", xlab = "Nombre de lancers", ylab = "Fréquence", xlim = c(0, max(simlist)))# Ajout de la moyenne théoriqueabline(v = 6, col = "red", lwd = 2, lty = 2)legend("topright", legend = c("Moyenne observée", "Moyenne théorique = 6"), col = c("blue", "red"), lty = c(1, 2), lwd = 2)
Show the code
import randomimport numpy as npimport matplotlib.pyplot as plt# Répétition de l'expériencerandom.seed(360)n =50000simlist = []for _ inrange(n): trial =0# valeur du lancer nb_tent =0# nombre de tentativeswhile trial !=6: nb_tent +=1 trial = random.randint(1, 6) # équivalent de sample(1:6,1) simlist.append(nb_tent)simlist = np.array(simlist)# Résultatsprint("\n=== Résultats de la simulation ===")print("Nombre de simulations:", n)print("Moyenne du nombre de lancers:", simlist.mean())print("Variance:", simlist.var(ddof=1))print("Écart-type:", simlist.std(ddof=1))print("Minimum:", simlist.min())print("Maximum:", simlist.max())print("Médiane:", np.median(simlist))# Calcul des moyennes cumuléesmean_values = np.cumsum(simlist) / np.arange(1, n +1)# Tracéplt.figure(figsize=(7, 4))plt.plot(mean_values, label="Moyenne empirique")plt.axhline(6, color="red", linestyle="--", label="Espérance théorique = 6")plt.xlabel("n (nombre d'expériences)")plt.ylabel("Moyenne empirique")plt.title("Convergence de la moyenne empirique vers l'espérance théorique")plt.legend()plt.grid(alpha=0.4)plt.show()
=== Résultats de la simulation ===
Nombre de simulations: 50000
Moyenne du nombre de lancers: 6.00114
Variance: 30.1522217448349
Écart-type: 5.4911038730691395
Minimum: 1
Maximum: 65
Médiane: 4.0
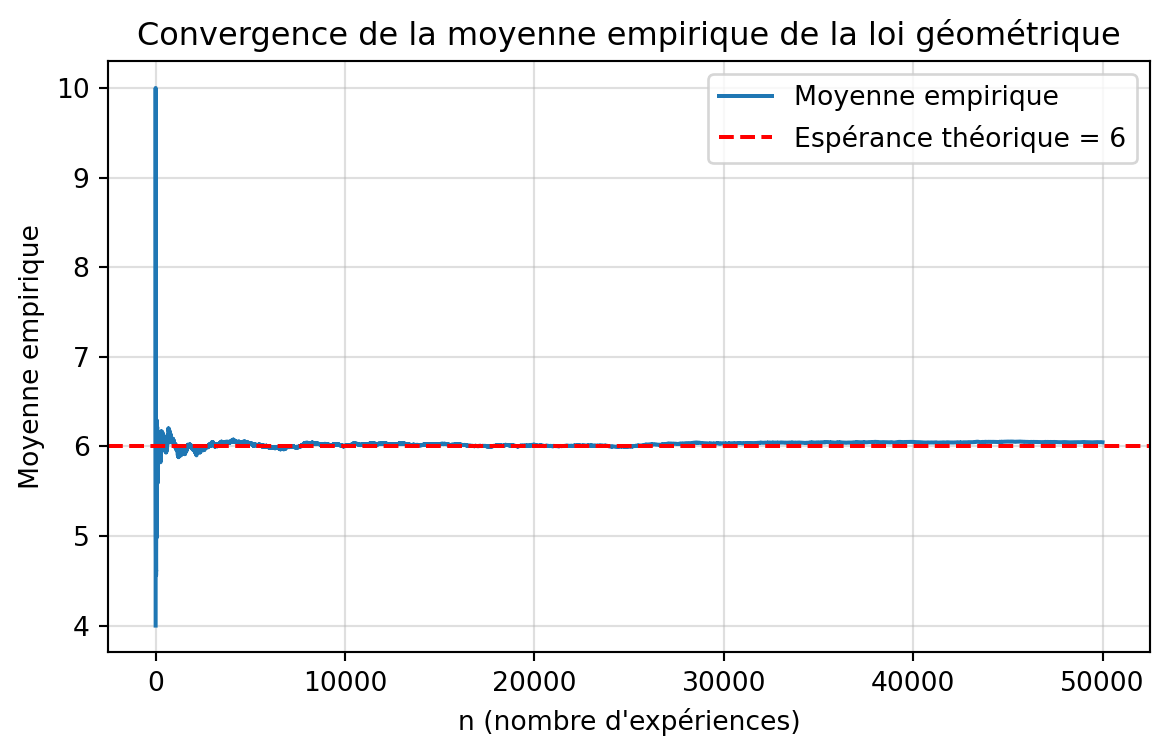
# Utilisation de la distribution géométrique# Alternative plus efficace à la simulation par boucleset.seed(360)n <- 50000p <- 1/6ctr <- 0simlist <- numeric(n)while (ctr < n) { ctr <- ctr + 1 # Génération d'une réalisation d'une loi géométrique # Attention, rgeom(n,p) donne le nombre d'échecs avant # le premier succès simlist[ctr] <- rgeom(1, p) + 1}# Affichage des résultatsmean(simlist)var(simlist)# Statistiques détailléescat("\n=== Résultats de la simulation (méthode géométrique) ===\n")cat("Nombre de simulations:", n, "\n")cat("Probabilité de succès (p):", p, "\n")cat("Moyenne observée:", mean(simlist), "\n")cat("Moyenne théorique:", 1/p, "\n")cat("Variance observée:", var(simlist), "\n")cat("Variance théorique:", (1-p)/p^2, "\n")cat("Écart-type observé:", sd(simlist), "\n")cat("Médiane:", median(simlist), "\n")# Comparaison graphiquepar(mfrow = c(1, 2))# Histogrammehist(simlist, breaks = 50, col = "lightgreen", border = "white", main = "Distribution du nombre de lancers\n(méthode rgeom)", xlab = "Nombre de lancers", ylab = "Fréquence", probability = TRUE)# Ajout de la moyenneabline(v = mean(simlist), col = "blue", lwd = 2)abline(v = 1/p, col = "red", lwd = 2, lty = 2)legend("topright", legend = c("Moyenne obs.", "Moyenne théo."), col = c("blue", "red"), lty = c(1, 2), lwd = 2, cex = 0.8)# QQ-plot pour vérifier la distributionqqplot(qgeom(ppoints(n), p) + 1, simlist, main = "QQ-Plot : Théorique vs Observé", xlab = "Quantiles théoriques (Géométrique)", ylab = "Quantiles observés", col = "darkgreen", pch = 20, cex = 0.5)abline(0, 1, col = "red", lwd = 2)par(mfrow = c(1, 1))# Méthode encore plus efficace (vectorisée)cat("\n=== Méthode vectorisée (plus rapide) ===\n")set.seed(360)simlist_vec <- rgeom(n, p) + 1cat("Moyenne:", mean(simlist_vec), "\n")cat("Variance:", var(simlist_vec), "\n")
Show the code
import numpy as npimport matplotlib.pyplot as pltimport scipy.stats as st# Paramètresnp.random.seed(360)n =50000p =1/6# La loi géométrique de R donne "nombre d'échecs avant succès"# => équivalent python : st.geom(p).rvs() renvoie déjà nb_tentatives# MAIS Python compte à partir de 1, donc c'est ce qu’on veut !simlist = st.geom(p).rvs(size=n)# Affichage des résultatsprint("\n=== Résultats de la simulation (méthode géométrique) ===")print("Nombre de simulations:", n)print("Probabilité de succès p:", p)print("Moyenne observée:", simlist.mean())print("Moyenne théorique:", 1/p)print("Variance observée:", simlist.var(ddof=1))print("Variance théorique:", (1- p) / p**2)print("Écart-type observé:", simlist.std(ddof=1))print("Médiane:", np.median(simlist))# Moyennes cumuléesmean_values = np.cumsum(simlist) / np.arange(1, n +1)# Tracéplt.figure(figsize=(7, 4))plt.plot(mean_values, label="Moyenne empirique")plt.axhline(1/p, color="red", linestyle="--", label=f"Espérance théorique = {1/p:.0f}")plt.xlabel("n (nombre d'expériences)")plt.ylabel("Moyenne empirique")plt.title("Convergence de la moyenne empirique de la loi géométrique")plt.legend()plt.grid(alpha=0.4)plt.show()
=== Résultats de la simulation (méthode géométrique) ===
Nombre de simulations: 50000
Probabilité de succès p: 0.16666666666666666
Moyenne observée: 6.04552
Moyenne théorique: 6.0
Variance observée: 29.974807425748512
Variance théorique: 30.000000000000004
Écart-type observé: 5.474925335175678
Médiane: 4.0
Exercice 4
Soient X et Y deux variables aléatoires de carré \(\mathbb{P}\)-intégrable.
Soit \(a \in \mathbb{R}\).
Écrire \[
E\big((|X| - a|Y|)^2\big)
\] sous la forme d’un polynôme en a, et calculer son discriminant \(\Delta\).
Expliquer pourquoi \(\Delta \le 0\), et en déduire l’inégalité de Hölder : \[
E(|XY|) \le \sqrt{E(X^2)} \, \sqrt{E(Y^2)}.
\]
En appliquant l’inégalité précédente à des variables bien choisies, en déduire que : \[
|\mathrm{Cov}(X,Y)| \le \sqrt{V(X)} \, \sqrt{V(Y)}.
\]
L’inégalité de Hölder se généralise sous la forme suivante (admise dans la suite).
Soient deux nombres réels \(p, q \ge 1\) conjugués, c’est-à-dire tels que : \[
\frac{1}{p} + \frac{1}{q} = 1.
\]
Soient X et Y deux variables aléatoires telles que \(\int |X|^p \, d\mathbb{P} < \infty\) et \(\int |Y|^q \, d\mathbb{P} < \infty\).
Alors : \[
E(|XY|) \le \big(E(|X|^p)\big)^{1/p} \, \big(E(|Y|^q)\big)^{1/q}.
\]
Soient maintenant deux réels \(r\) et \(s\) tels que \(1 < r < s < \infty\).
Soit \(Z\) une variable aléatoire telle que \(\int |Z|^s \, d\mathbb{P} < \infty\).
Vérifier que les réels \(\frac{s}{r}\) et \(\frac{s}{s-r}\) sont conjugués.
En appliquant l’inégalité de Hölder avec des variables aléatoires \(X\) et \(Y\) bien choisies, montrer que : \[
E(|Z|^r) \le \big(E(|Z|^s)\big)^{r/s}.
\]
En déduire que si une variable aléatoire \(Z\) admet un moment d’ordre \(s > 1\), alors elle admet un moment d’ordre \(r\) pour tous les réels \(1 < r < s\).
Correction de l’exercice 4
Calcul de \(E\big((|X| - a|Y|)^2\big)\)
Nous avons en utilisant la linéarité de l’espérance :
Comme \(E\big((|X| - a|Y|)^2\big) \geq 0\) pour tout \(a \in \mathbb{R}\), le polynôme ne peut pas avoir deux racines réelles distinctes, donc \(\Delta \leq 0\).
En appliquant l’inégalité précédente en remplaçant \(X\) par \(X - E(X)\), et \(Y\) par \(Y - E(Y)\), nous obtenons :
\[
E \big( \{ X - E(X) \} \{ Y - E(Y) \} \big)
\le \sqrt{E \big( \{ X - E(X) \}^2 \big)} \, \sqrt{E \big( \{ X - E(X) \}^2 \big)}.
\]
Nous avons ensuite
\[
|\mathrm{Cov}(X,Y)|
= \big| E \big( \{ X - E(X) \} \{ Y - E(Y) \} \big) \big|
\le E \big( \{ X - E(X) \} \{ Y - E(Y) \} \big),
\]
ce qui donne le résultat voulu.
Nous avons bien
\[
\frac{r}{s} + \frac{s - r}{s} = 1.
\]
En appliquant l’inégalité de Hölder générale aux variables aléatoires \(X = Z^r\) et \(Y = 1\), et avec les nombres conjugués \(\frac{s}{r}\) et \(\frac{s}{s-r}\), nous obtenons
\[
E \big( |Z^r \times 1| \big)
\le \Big( E \big( |Z^r|^{\frac{s}{r}} \big) \Big)^{\frac{r}{s}}
\Big( E \big( |1|^{\frac{s}{s-r}} \big) \Big)^{\frac{s-r}{s}}
= \Big( E(|Z|^s) \Big)^{\frac{r}{s}}.
\]